
⏱ 5-minute read
Many of you have already tried this. You connected Shopify to Claude. Maybe Klaviyo too. You asked a real question – which products are compounding repeat? why is payback slipping? – and got something that looked like an answer. Then you looked closer: generic, and some of the numbers were wrong.
That’s not a Claude problem. It’s a data‑layer problem. It’s missing the context.
This week we're releasing our own answer to that: a RetentionX MCP for Claude, and a set of skills built on top of it.

A raw-data MCP gives the model a database. A commerce data layer gives it context.
Raw-data MCPs, including Shopify's, expose what your database exposes: orders, customers, line items. To answer "are May cohorts worse than April," Claude has to assemble the cohort from millions of rows. It can't. It samples, joins, and fills the gaps from training data. That's where the wrong numbers come from.
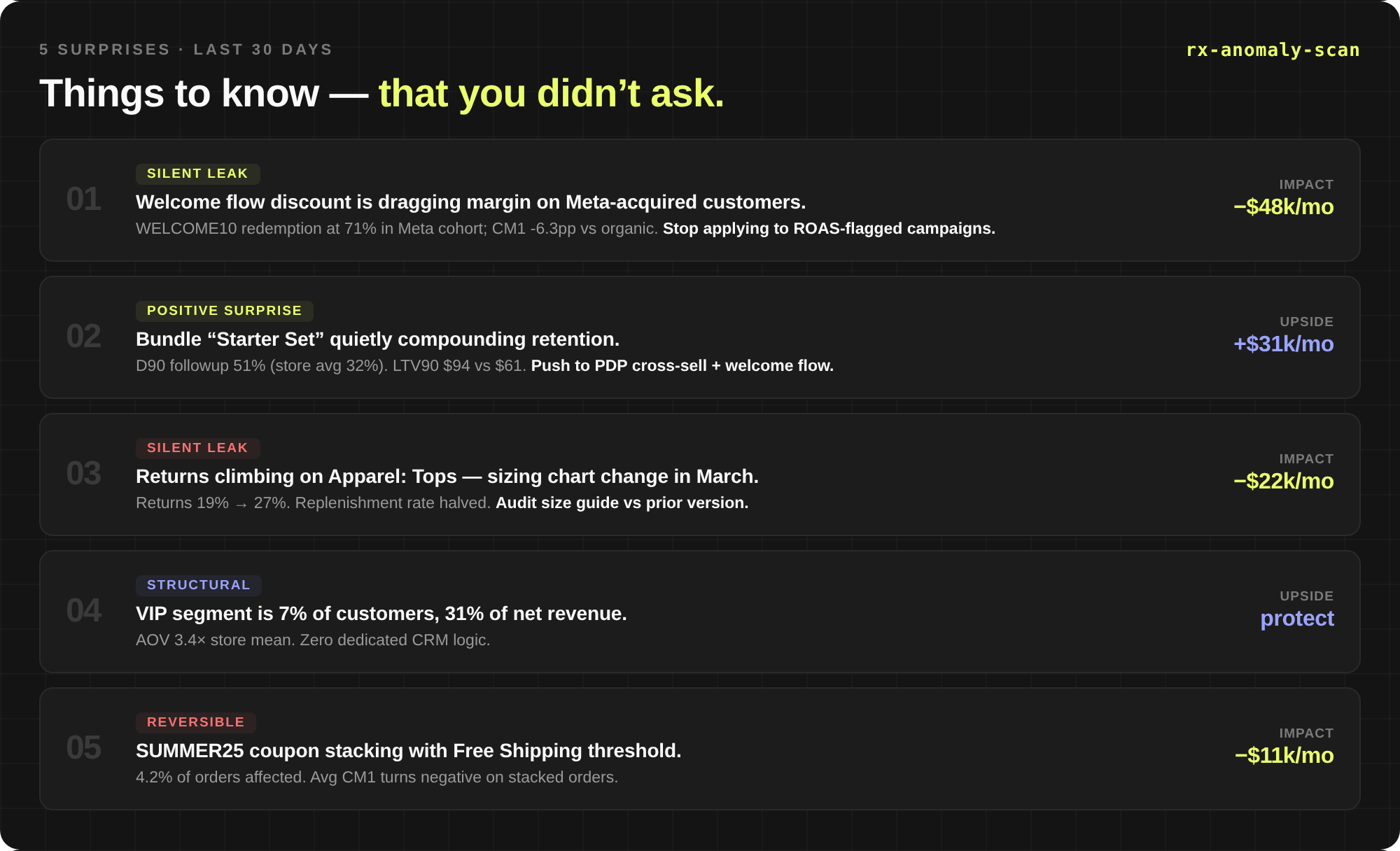
The same gap explains why those connections never answer the second-layer questions: which channel? which product? which discount? No raw schema exposes those dimensions pre-built.
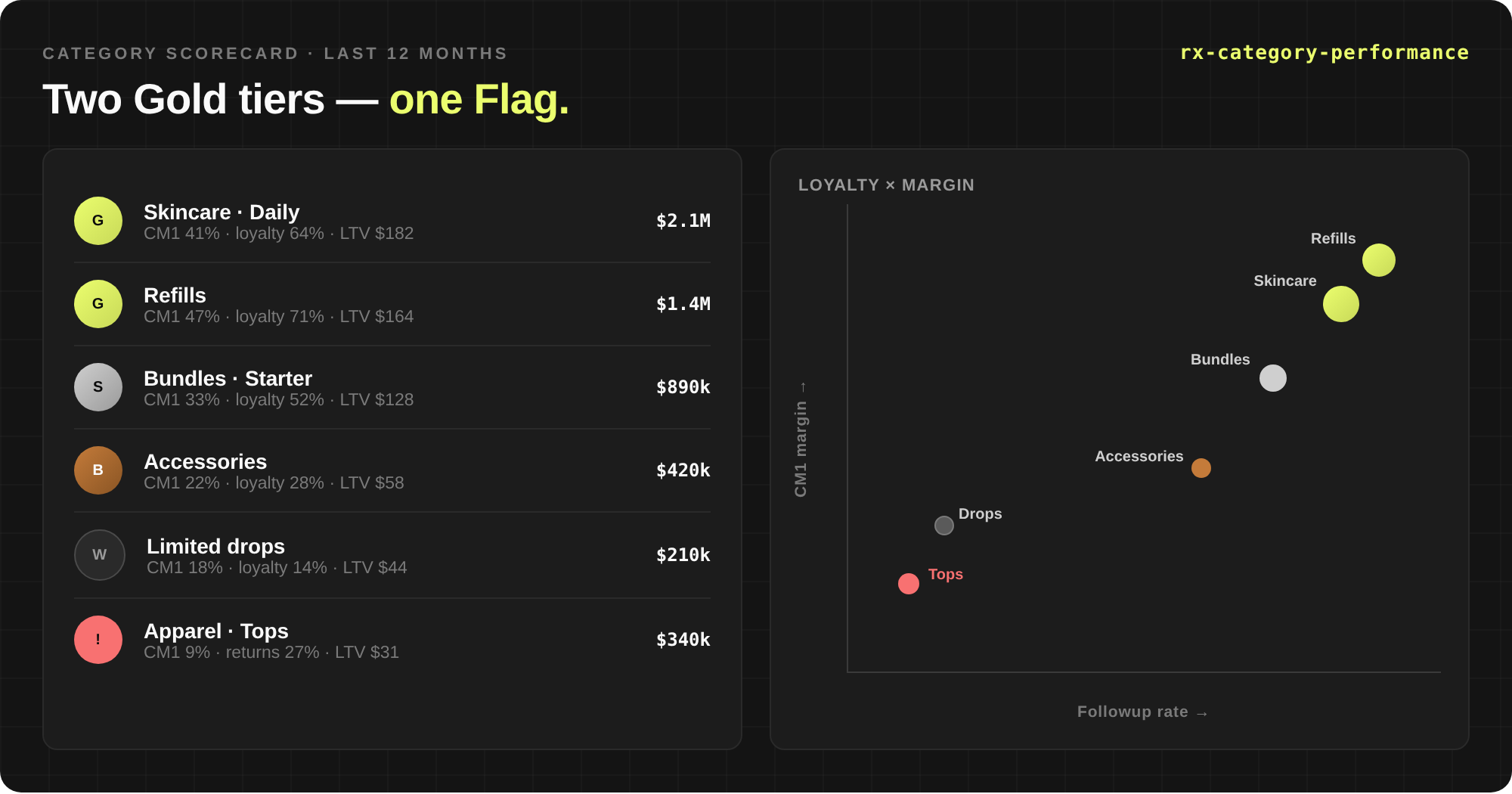
The RetentionX MCP is not a connection to your store's database. It's a connection to a commerce intelligence layer. Cohort retention curves, follow-up rate per product, replenishment timing, LTV horizons, payback windows, segment-level P&L, brand stickiness, category quality, already computed, already structured, ready to read.
That changes two things at once.

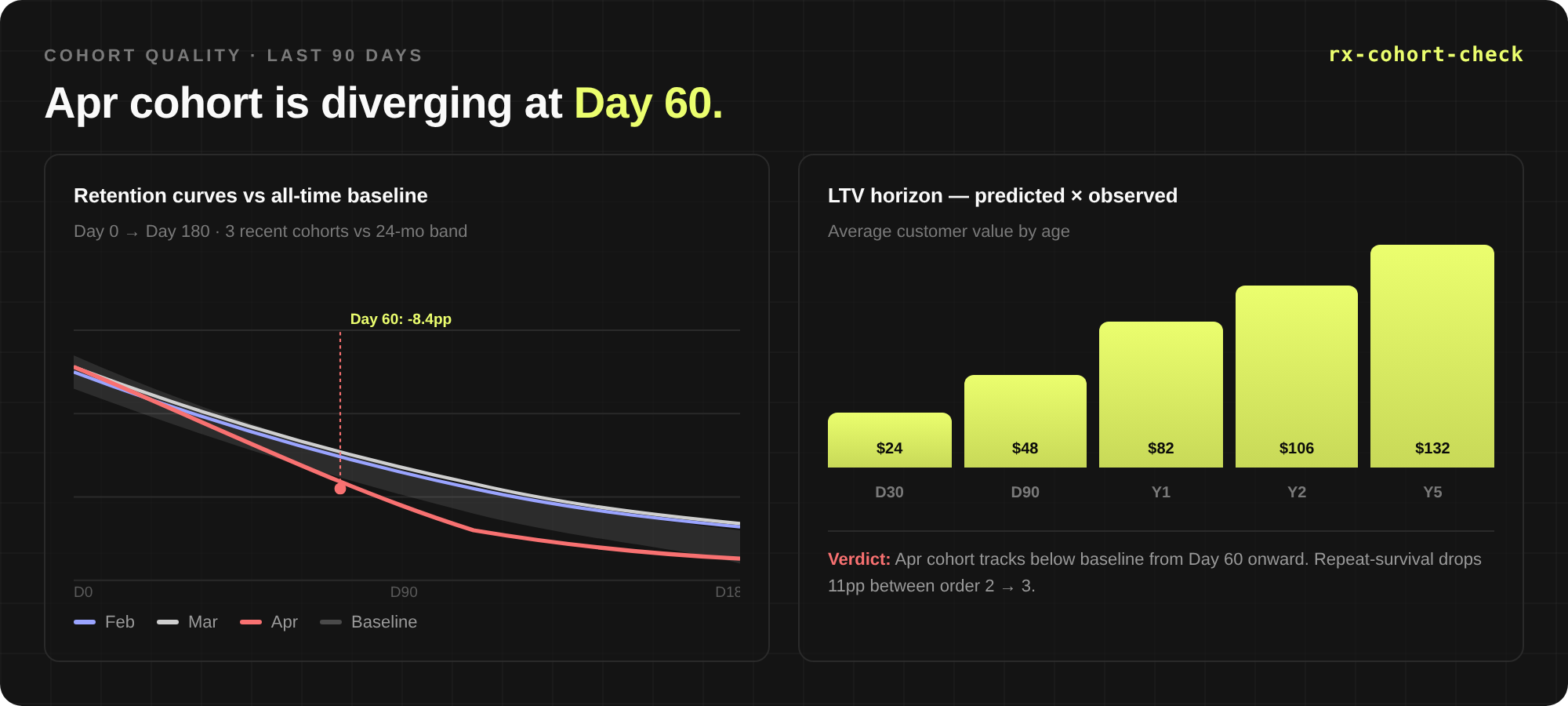
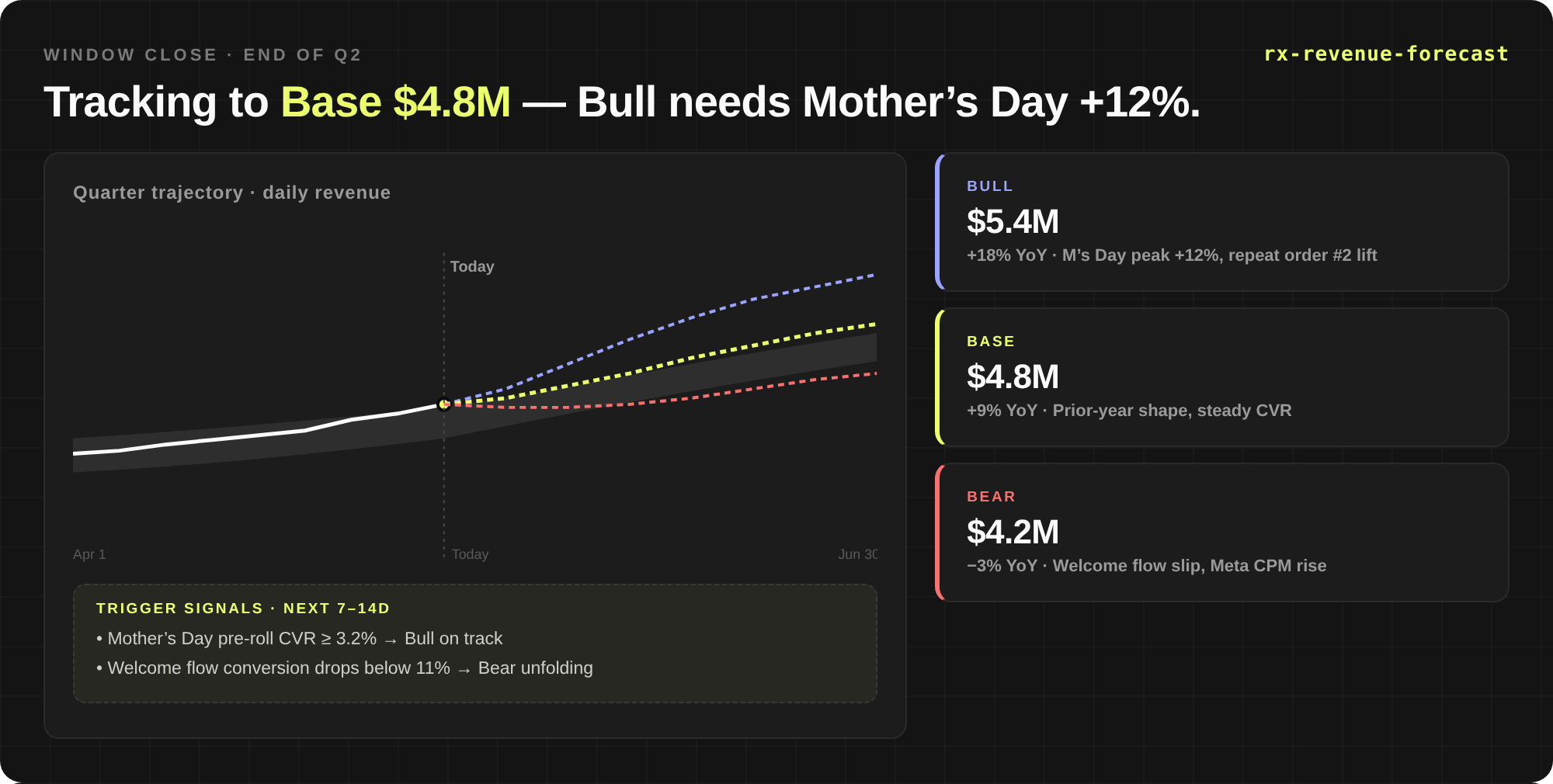
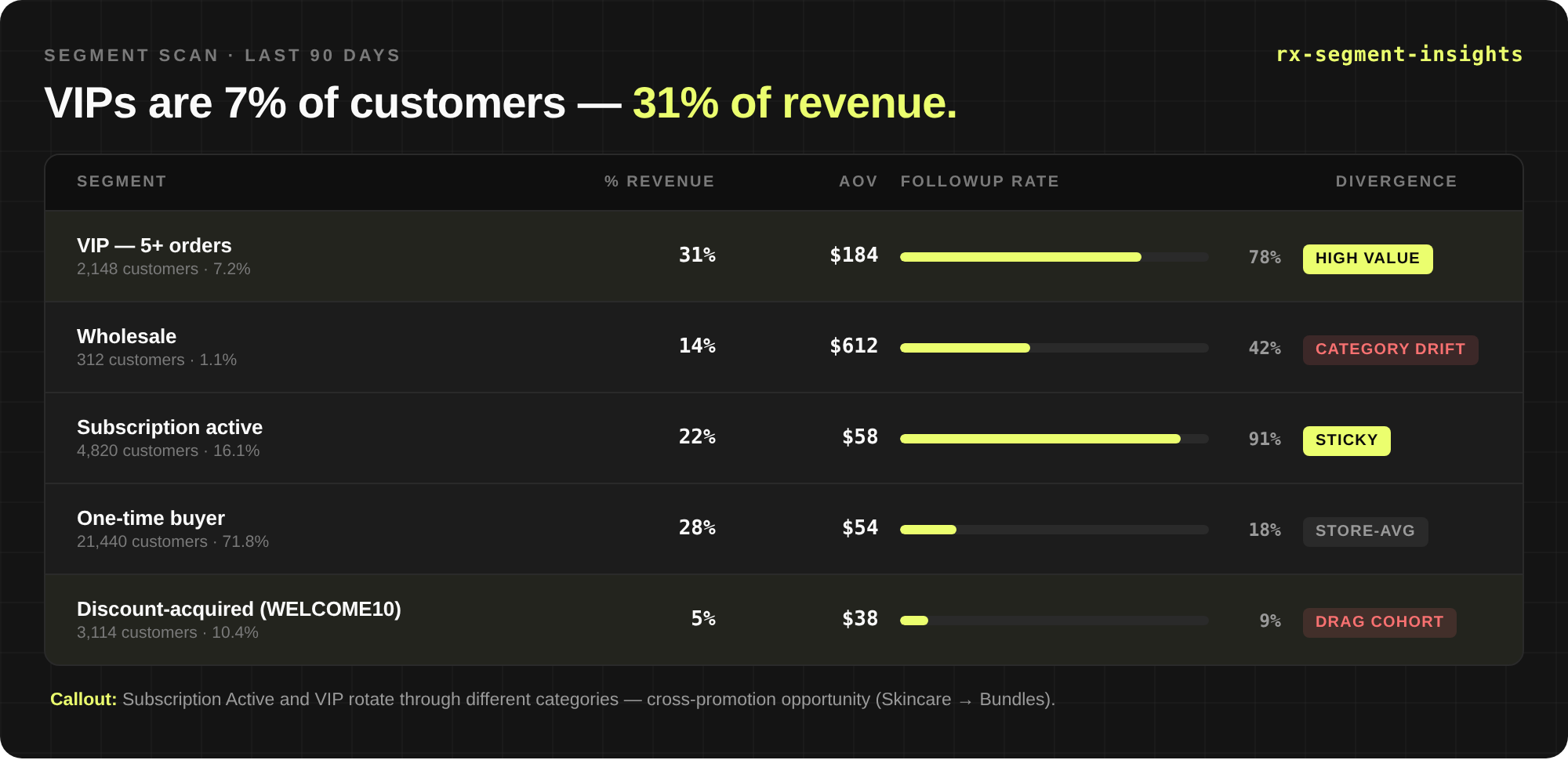
Depth. Because every dimension is pre-computed, the second question is free. You don’t ask “what’s my retention.” You ask it by acquisition product, for Meta-acquired customers, last quarter, against baseline — in four pivots without changing tools. This is where connections, anomalies, and root causes start surfacing.
Trust. Structured answers mean zero hallucination. Claude isn’t guessing what LTV90 means or estimating follow-up rate from a sample — it’s reading a number out of a defined contract. If the layer doesn’t have it, it says so. Instead of inventing it.
Pre-Built Claude Workflows For Commerce
Below are six skills. Each one demonstrates what this layer makes possible. They're not the product, every question you bring is one query away.
|

The dashboard era was about making humans interpret data. The raw-data MCP era was about making models assemble data. What's next is neither: a structured commerce layer the model reads – and the operator asks.
We offer a 30-day free trial of RetentionX, including all Claude MCP functionality.

 Listen on Spotify
Listen on Spotify
